Естественный интерес ряда исследовательских групп (среди них Оксфордский и Техасский университеты, Массачусетский технологический институт, лаборатории Беркли, Санди и Рокфеллера) вызвали природные способы хранения и обработки информации в биологических системах. Итогом их изысканий явился гибрид информационных и молекулярных технологий, а также достижений биохимии – биологический компьютер.
Идут разработки нескольких типов биокомпьютеров, которые базируются на различных биологических процессах. Это, в первую очередь, находящиеся в стадии разработки ДНК-компьютеры и клеточные биокомпьютеры.
ДНК-компьютеры. В живых клетках генетическая информация закодирована в молекуле ДНК (дезоксирибонуклеиновой кислоты). ДНК – это полимер, состоящий из субъединиц, называемых нуклеотидами. Нуклеотид представляет собой комбинацию сахара (дезоксирибозы), фосфата и одного из четырех входящих в состав ДНК азотистых оснований: аденина (А), тимина (Т), гуанина (G) и цитозина (C). Молекула ДНК образует спираль, состоящую из двух цепей, объединенных водородными связями. При этом основание А одной цепи может соединяться водородными связями только с основанием Т другой цепи, а основание G – только с основанием С. Имея одну из цепей ДНК, всегда можно восстановить строение второй.
Благодаря этому фундаментальному свойству ДНК, получившему название комплементарности, генетическая информация может точно копироваться и передаваться от материнских клеток к дочерним клеткам. Репликация молекулы ДНК происходит за счет работы специального фермента ДНК-полимеразы. Этот фермент скользит вдоль ДНК и синтезирует на ее основе новую молекулу, в которой все основания заменены на соответствующие парные. Причем фермент начинает работать, когда к ДНК прикрепился коротенький кусочек – «затравка» (праймер).
В клетках существует также родственная молекуле ДНК молекула матричной рибонуклеиновой кислоты (РНК). Она синтезируется специальным ферментом, использующим в качестве образца одну из цепей ДНК, и комплементарна по отношению к ней. Именно на молекуле РНК, в клетке, как на матрице, с помощью специальных ферментов и вспомогательных факторов происходит синтез белков. Молекула РНК химически устойчивее, чем ДНК, поэтому экспериментаторам с ней работать удобнее. Последовательность нуклеотидов в цепи ДНК / РНК определяет генетический код. Единицей генетического кода – кодоном – является последовательность из трех нуклеотидов. Ученые решили попытаться, по примеру природы, использовать молекулы ДНК для хранения и обработки данных в биологических компьютерах.
Первым из них был Леонард Эдлмен из университета Южной Калифорнии, сумевший решить задачу гамильтонова пути. Суть ее в том, чтобы найти маршрут движения с заданными точками старта и финиша между несколькими городами, в каждом из которых разрешается побывать только один раз. «Дорожная сеть» представляет собой однонаправленный граф. Эта задача решается прямым перебором, однако при увеличении числа городов сложность ее возрастает экспоненциально (для цепочек ДНК число таких пунктов («городов») равно семи, т.е. n = 7). Каждый такой «город» Эдлмен идентифицировал уникальной последовательностью из 20 нуклеотидов.
Тогда путь между любыми двумя городами будет состоять из второй половины кодирующей последовательности для точки старта, и первой половины кодирующей последовательности для точки финиша (молекула ДНК, как и вектор, имеет направление).
Синтезировать такие последовательности современная молекулярная аппаратура позволяет очень быстро. В итоге последовательность ДНК с решением составит 140 нуклеотидов (7x20). Остается только синтезировать и выделить такую молекулу ДНК. Для этого в пробирку помещается около 100 триллионов молекул ДНК, содержащих все возможные 20-нуклеотидные последовательности, кодирующие города и пути между ними. Далее за счет взаимного притяжения нуклеотидов А–Т и G–C отдельные цепочки ДНК сцепляются друг с другом случайным образом, а специальный фермент лигаза сшивает образующиеся короткие молекулы в более крупные образования. При этом синтезируются молекулы ДНК, воспроизводящие все возможные маршруты между городами. Нужно лишь выделить из них те, что соответствуют искомому решению. Эдлмен решил эту задачу биохимическими методами, последовательно удалив сначала цепочки, которые не начинались с первого города – точки старта – и не заканчивались местом финиша, затем те, что содержали более семи городов или не содержали хотя бы один. Легко понять, что любая из оставшихся после такого отбора молекула ДНК представляет собой решение задачи.
Вслед за работой Эдлмена последовали и другие. Ллойд Смит из университета Висконсин решил с помощью ДНК задачу доставки четырех сортов пиццы по четырем адресам, которая подразумевала 16 вариантов ответа. Ученые из Принстонского университета решили комбинаторную шахматную задачу: при помощи РНК нашли правильный ход шахматного коня на доске из девяти клеток (всего их 512 вариантов).
Ричард Липтон из Принстона впервые показал, как, используя ДНК, кодировать двоичные числа и решать логические выражения. Имея такое выражение, включающее n переменных, нужно найти все комбинации значений переменных, делающих выражение истинным. Задачу можно решить только перебором 2n комбинаций. Все эти комбинации легко закодировать с помощью ДНК, а дальше действовать по методике Эдлмена. Липтон предложил даже способ взлома шифра DES (американский криптографический шифр), трактуемого как своеобразное логическое выражение.
Первую модель биокомпьютера в виде механизма из пластмассы в 1999 г. создал И. Шапиро из института естественных наук Вейсмана.
Модель имитировала работу молекулярной машины в живой клетке, собирающей белковые молекулы по информации с ДНК, используя РНК
в качестве посредника между ДНК и белком. В 2001 г. Шапиро удалось реализовать модель в реальном биокомпьютере, который состоял из молекул ДНК, РНК и специальных ферментов. Молекулы фермента выполняли роль аппаратного, а молекулы ДНК – программного обеспечения. В одной пробирке помещалось около триллиона элементарных вычислительных модулей. В результате скорость вычислений достигала миллиарда операций в секунду, а точность – 99,8 %.
Пока биокомпьютер Шапиро может применяться лишь для решения самых простых задач, выдавая всего два типа ответов: «истина» или «ложь». В проведенных экспериментах за один цикл все молекулы ДНК параллельно решали единственную задачу. Однако потенциально они могут трудиться одновременно над разными задачами, в то время как традиционные ПК являются, по сути, однозадачными.
В 2002 г. фирма Olympus Optical объявила о создании ДНК–компьютера, предназначенного для генетического анализа. Машина создана в сотрудничестве с биологом Акирой Тояма из Токийского университета. Компьютер имеет молекулярную и электронную составляющие. Первая осуществляет химические реакции между молекулами ДНК, обеспечивает поиск и выделение результата вычислений. Вторая – обрабатывает информацию и анализирует полученные результаты. Сейчас анализ генов выполняется вручную и требует много времени: при этом формируются многочисленные фрагменты ДНК и контролируется ход химических реакций. Когда ДНК-компьютинг будет использоваться для генетического анализа, то задачи, которые ранее выполнялись в течение трех дней, будут решаться за шесть часов. Технология генетического анализа на основе ДНК–компьютера находит применение в медицине и фармацевтике. Ученые планируют внедрять молекулярные наноустройства в тело человека для мониторинга состояния его здоровья и синтеза необходимых ему лекарств.
Возможностями биокомпьютеров заинтересовались и военные. Американское агентство по исследованиям в области обороны DARPA выполняет проект под названием BioComp. Его цель – создание мощных вычислительных систем на основе ДНК. Попутно исследователи надеются научиться управлять процессами взаимодействия белков и генов. Для этого планируется создать мощный симулятор BioSPICE, способный средствами машинной графики визуализировать биомолекулярные процессы.
Клеточные компьютеры. Еще одним перспективным направлением биокомпьютинга является создание клеточных компьютеров. Для этой цели идеально подходят бактерии, если бы в их геном удалось включить некую логическую схему, которая могла бы активизироваться в присутствии определенного вещества. Такие компьютеры очень дешевы в производстве. Им не нужна столь стерильная атмосфера, как при производстве полупроводников. И единожды запрограммировав клетку, можно легко и быстро вырастить тысячи клеток с такой же программой.
В 2001 г. в США были созданы трансгенные микроорганизмы (микроорганизмы с искусственно измененными генами), клетки которых могут выполнять логические операции И и ИЛИ. Учёные использовали способность генов синтезировать тот или иной белок под воздействием определенной группы химических раздражителей. Генетический код бактерий Pseudomonas putida был изменён таким образом, что их клетки обрели способность выполнять простые логические операции. Например, при выполнении операции И в клетку подаются два вещества (входные операнды), под влиянием которых ген вырабатывает определенный белок. Ученые создают на базе этих клеток более сложные логические элементы, а также ищут возможности создания клетки, выполняющей параллельно несколько логических операций.
Элементная база биологических компьютеров. Для разработки таких компьютеров нужно получить базовые элементы. Предложений поступает очень много. Так, исследователи израильского института «Технион» создали самособирающийся нанотранзистор, для разработки которого они использовали особенности структуры ДНК и электронных свойств углеродных нанотрубок. Сначала частицы молекулы ДНК покрыли белками бактерии «E. Coli», после этого связали с ДНК покрытые антителами нанотрубки, затем в процессе создания устройства использовали ионы золота и серебра. Получившаяся в результате конструкция работает как транзистор.
В 2004 году исследователи разработали микроскопические устройства, которые можно внедрять в кровоток. Они могут диагностировать онкологические заболевания и выпускать в нужном месте необходимую дозу лекарства. Устройства построены на базе синтетических ДНК, часть цепи служит для определения высокой концентрации РНК определенного вида, которые вырабатываются раковыми клетками, другая часть молекулярной цепи является хранилищем и управляющей структурой для еще одной нуклеотидной последовательности лекарства. Этот фрагмент ДНК, выпущенный в нужном месте, подавляет активность гена, вовлеченного в процесс развития рака. Ученые продемонстрировали несколько деталей биологической молекулярной машины, которая успешно идентифицировала в пробирке клетки, соответствующие раку простаты и раку легких. До полноценного устройства, которое можно было бы применять в борьбе с раковыми заболеваниями, еще далеко, однако ученые сделали важный шаг на пути создания молекулярных медицинских ДНК-роботов.
В том же году профессор Ричард Киль и его коллеги из университета штата Миннесота, США, разработали экспериментальные биоэлектронные схемы. Американские ученые использовали цепочки ДНК для создания плоской ткани, напоминающей застежку-липучку на уровне наноструктур. Проводимые опыты продемонстрировали, как искусственные фрагменты ДНК самостоятельно собрались в заранее рассчитанную наноструктуру. С регулярным шагом на этой структуре образовались липучки, которые способны принять другие сложные органические молекулы или различные металлы. Авторы проекта закрепляли такие молекулы на ткани, сформированной ДНК, будто радиодетали на пластмассовой плате.
Нанокомпоненты, собранные на основе ДНК, теоретически могут создать схему с характерным расстоянием между деталями в одну треть нанометра. А поскольку такие компоненты могут сохранять электрические или магнитные заряды, испытываемая в Миннесоте технология – это прообраз будущей технологии создания сверхбыстродействующих электронных схем с высокой плотностью упаковки информации. Они будут совмещать органические и неорганические компоненты.
В 2005 г. Юнсэон Чой из университета штата Мичиган, США, применил молекулы ДНК для построения наночастиц с заданными свойствами. Использовались так называемые дендримеры (крошечные разветвленные полимеры), концы которых могут содержать различные молекулы. Сначала были синтезированы отдельные звенья дендримеров, причём каждое звено снабжалось молекулой лекарства и небольшим фрагментом половинки ДНК. При смешивании всех этих ингредиентов, ДНК соединялись с дополнительными парами оснований. Короткие звенья полимера автоматически сшивались в длинные комплексы. Дендримеры могут избирательно поставлять пять отдельных лекарств пяти видам клеток. Синтез молекулы по методике Чоя занимает 10 шагов вместо 25, при использовании прежних технологий. Недостаток технологии состоит в том, что синтез нужных цепочек может занимать по несколько месяцев.
Исследователь Нью-Йоркского университета Нэд Симэн создал наномашину, производящую единственный полимер, повторяющий структуру самого устройства, с размерами 110x30x2 нм. Аппарат состоит из ДНК-машин, которые работают на основе определенных комбинаций цепочек молекул ДНК. У исследователя есть уверенность в том, что ему удастся создать ДНК-машину, работающую подобно молекуле РНК. Свое применение будущая искусственная рибосома найдет в синтезе новых материалов по заданной последовательности, закодированной в ДНК. В конце концов, можно научиться делать полимеры и новые материалы в больших количествах и за малый промежуток времени благодаря ДНК-машинам, уверен Симэн.
Билл Дитто из Технологического института штата Джорджия, США, провел эксперимент, подсоединив микродатчики к нескольким нейронам пиявки. Он обнаружил, что в зависимости от входного сигнала нейроны образуют новые взаимосвязи. Отсюда можно сделать вывод, что биологические компьютеры, состоящие из нейронно-подобных элементов (нейроэлементов), в отличие от кремниевых устройств, смогут самостоятельно искать нужные решения, посредством самопрограммирования. Исследователь намерен использовать результаты своей работы для создания искусственного мозга роботов будущего.
В настоящее время область ДНК-вычислений пребывает на этапе подтверждения концепции, когда возможность реального применения уже доказана. Можно утверждать, что в ближайшие десятилетия технология продемонстрирует свои реальные возможности. Сейчас происходит оценка того, насколько полезны или вредны ДНК-компьютеры для человечества. Применение в вычислительной технике биологических материалов позволит со временем уменьшить компьютеры до размеров живой клетки. Пока это выглядит как чашка Петри, наполненная спиралями ДНК, или как нейроны, взятые у пиявки и подсоединенные к электрическим проводам.
По существу, наши собственные клетки – это не что иное, как биологические машины молекулярного размера, а примером биокомпьютера служит наш мозг.
Если бы модель биологического компьютера Ихуда Шапиро, упоминавшаяся ранее, состояла из настоящих биологических молекул, то его размер был бы равен величине одного из компонентов клетки – 0,000 025 мм. По мнению исследователя, современные достижения в области сборки молекул позволяют создавать устройства клеточного размера, которое можно применять для биомониторинга. Более традиционные ДНК-компьютеры в настоящее время используются для расшифровки генома живых существ. Пробы ДНК применяются для определения характеристик другого генетического материала: благодаря правилам спаривания спиралей ДНК, можно определить возможное расположение четырех базовых аминокислот (A, C, T и G).
Потенциал биокомпьютеров очень велик. По сравнению с обычными вычислительными устройствами они имеют ряд уникальных особенностей. Во-первых, они используют не бинарный, а тернарный код (так как информация в них кодируется тройками нуклеотидов). Во-вторых, поскольку вычисления производятся путем одновременного вступления в реакцию триллионов молекул ДНК, они могут выполнять до 1015 операций в секунду. Правда, извлечение результатов вычислений предусматривает несколько этапов очень тщательного биохимического
анализа и осуществляется гораздо медленнее. В-третьих, вычислительные устройства на основе ДНК хранят данные с плотностью, в триллионы раз превышающей показатели оптических дисков. И, главное, ДНК-компьютеры имеют исключительно низкое энергопотребление.
Однако при разработке биологических компьютеров многие ученые столкнулись с целым рядом серьезных проблем. Первая связана со считыванием результатов вычислений – современные способы секвенирования (распознавания кодирующей последовательности) пока несовершенны: невозможно за один раз распознать цепочки длиной более нескольких тысяч оснований – это весьма дорогостоящая, сложная и трудоемкая операция. Вторая проблема – ошибки в вычислениях. Для химиков и биологов точность при синтезе и секвенировании оснований в 1 % считается очень хорошей. Но для информационных технологий она неприемлема: решения задачи могут потеряться, когда молекулы просто прилипают к стенкам сосудов; кроме того, нет никаких гарантий, что в ДНК не возникнут точечные мутации, и т.п.
Кроме того, молекулы ДНК с течением времени могут распадаться, и тогда результаты вычислений просто исчезают на глазах! Клеточные компьютеры, по сравнению с другими, работают довольно медленно, и их легко «сбить с толку», намеренно или ненамеренно нарушив вычислительный процесс. С этими проблемами ученые активно борются, но насколько им удастся преуспеть – покажет ближайшее время. В любом случае, для специалистов – биоинформатиков открываются большие перспективы. Однако биокомпьютеры на широкие массы пользователей не рассчитаны.
В перспективе нанокомпьютеры на основе ДНК смогут взаимодействовать с клетками человека, осуществлять наблюдение за потенциальными болезнетворными изменениями и синтезировать лекарства для борьбы с ними. С помощью клеточных компьютеров станет возможным объединение информационных технологий с биотехнологиями. Они смогут управлять биохимическими процессами, регулировать биологические реакции внутри человеческого организма, производить гормоны и лекарственные вещества, а также доставлять к определенному больному органу пациента необходимую дозу лекарств, и др.
Американским учёным удалось показать, что для сложнейших расчётов не обязательно иметь суперкомпьютер – вместо этого можно обойтись пробиркой с бактериями. Предварительные результаты эксперимента по созданию прототипа биологического вычислительного устройства на основе ДНК живых микроорганизмов были опубликованы в Journal of Biological Engineering.
О способности ДНК хранить и обрабатывать информацию известно давно: генетики подсчитали, что в одной цепочке молекулы может храниться такой же объём данных, как в 1000 книгах по 500 страниц в каждой.
Естественно, перед исследователями встал вопрос о возможности использования этого уникального ресурса: соответствующие разработки проводятся более 10 лет. В частности, мы уже писали о клетках с искусственной генетической памятью и о синтетической биологии , которая занимается в том числе программированием генетических свойств микроорганизмов.
Группе учёных из колледжа Дэвидсона (Davidson College) и университета Миссури (Missouri Western State University) под руководством Кармэллы Хейнес (Karmella Haynes) впервые удалось не в теории, а на практике продемонстрировать вычислительные возможности ДНК на примере бактерий E. сoli .
Исследователи использовали уже упомянутый принцип – способность цепочки нуклеотидов обрабатывать большие массивы данных. Для большей наглядности они обратились к известной в математике и вычислительной технике задачке о подгоревших блинах, оптимальное решение которой в далёком 1979 году опубликовал – да-да – сам Билл Гейтс.
Суть задачки очень проста: в её классическом варианте необходимо за минимальное количество переворачиваний расположить блины разного диаметра в наиболее устойчивом порядке. Заметьте: только переворачивать – не перекладывать! В приведённом на иллюстрации простейшем примере оптимальное решение достигается за два «оборота». Подгоревшие блины – более «продвинутая» версия, где сортировку необходимо провести так, чтобы все блины в итоге лежали не только устойчиво, но ещё и подгоревшей стороной вниз (иллюстрация Todd Eckdahl и Jeff Poet).
Итак, смысл задачи о подгоревших блинах состоит в поиске минимального числа перестановок. На самом деле эта «незатейливая» головоломка из комбинаторики демонстрирует одну из основных функций, которую выполняют компьютеры, – обработку больших массивов информации с помощью перестановки (транспонирования) порций данных (chunks of data).
Аналогичный эффект удалось реализовать доктору Хейнес и её коллегам – путём комбинирования различных генов и их перестановки. В ходе эксперимента отдельные участки ДНК играли роль блинов. С помощью специально добавленного фермента экспериментаторы добились возможности влиять на перестановку этих участков в зависимости от реакции на антибиотик тетрациклин.

Бактерии E.сoli не обладают собственной системой рекомбинации генов, но являются детально изученными и хорошо понятными объектами для наблюдения. В связи с этим исследователи сделали им upgrade, снабдив клеточным механизмом управления ДНК – ферментом Hin рекомбиназа. При определённом расположении и ориентации «включалась» устойчивость к раздражителю (иллюстрация Todd Eckdahl и Jeff Poet).
Но самое главное: учёным удалось расположить «вставки» таким образом, что активность гена, ответственного за устойчивость к антибиотику, проявлялась только тогда, когда все блоки ДНК выстраивались в заданной последовательности.
При этом количество рекомбинаций, необходимых бактериям для формирования устойчивости, равнозначно минимальному числу переворотов подгоревших блинов, которые необходимо сделать согласно условию приведённой выше задачки.
По словам авторов исследования, аналогичные вычисления в чашке Петри, содержащей миллиарды микроорганизмов, теоретически позволят запустить настоящий вычислительный симбиоз: ведь каждая бактерия в данном случае – прототип биологического компьютера.
НАЦИОНАЛЬНЫЙ ИССЛЕДОВАТЕЛЬСКИЙ
ЯДЕРНЫЙ УНИВЕРСИТЕТ
МОСКОВСКИЙ ИНЖИНЕРНО ФИЗИЧЕСКИЙ ИНСТИТУТ
(НИЯУ МИФИ)
Факультет автоматики и электроники, группа А4-11
Биокомпьютеры
Выполнила:
Студент группы А4-11
Потемкина Т.С.
Преподаватель:
Доцент Лапшинский В.А.
Москва 2011
Глава 1. Биоинформатика
Глава 2. Введение в историю биокомпьютеров
2.1. Биокомпьютеры – что это?
2.2. Истоки. Расцвет биотехнологии
2.3. Потенциальные возможности
Глава 3. Строение биокомпьютера
3.3. Живая память
3.4. Начинка
Глава 4. Виды биокомпьютеров
4.1. ДНК-компьютеры
4.2. Клеточные компьютеры
Глава 5. Аргументы за и против введения новой технологии
Заключение
Список литературы
Глава 1
Биоинформатика
История развития биоинформатики как отдельной науки очень интересна. До нее существовали две других науки: геномика и протеомика.
Геномика - отрасль биологии, изучающая гены человека. Десять лет назад никто не мог поверить, что возможно расшифровать гены человека. В наше время геном человека полностью расшифрован, поэтому геномика практически утратила свое значение.
Из геномики плавно вытекает протеомика - наука, которая изучает белки, содержащиеся в живых организмах. Именно протеомика положила начало биоинформатике, так как электронный анализ вещества без “интеллектуального сравнения” занял бы десятки, а то и сотни лет. Наука, надо сказать, не для средних умов.
Итак, биоинформатика. Сама наука появилась недавно, в конце 90-х годов. Изначально она занималась поиском лекарств при помощи изучения белковых ферментов. Если полвека назад ученые тратили всю жизнь, чтобы изучить структуру одного белка, то теперь всего за несколько часов реально оценить 2,5 тысячи ферментов.
Значение этой науки очень велико. К примеру, вакцина от вируса гепатита была найдена благодаря биоинформатике. С помощью быстрого обследования можно практически на 100% быть уверенным в правильности диагноза или за несколько секунд определить отсутствие или наличие в организме заданного гена.
Кстати, белок в качестве живого вещества был выбран не случайно. Выяснилось, что для синтеза аминокислот (а биоинформатика изначально и предназначалась для этих целей) белок лучше всего расшифровывает искомую комбинацию генов. К тому же, некоторые белки совершенно неприхотливы к внешним воздействиям, хотя и реагируют на любое соприкосновение даже с отдельной молекулой инородного вещества.

Рис 1. «Модель биокомпьютера»
Глава 2
Введение в историю биокомпьютеров
2.1. Биокомпьютеры - что это?
Биокомпьютеры представляют собой гибрид информационных технологий и биохимии. Исследователи из различных областей науки (биологии, физики, химии, генетики, информатики) пытаются использовать реальные биологические процессы для создания искусственных вычислительных схем. Существует несколько принципиально различных типов биологических компьютеров, основанных на различных биологических процессах: искусственные нейронные цепи, эволюционное программирование, генные алгоритмы, ДНК-компьютеры и клеточные компьютеры. Первые два стали исследоваться еще в начале 40-х годов, но до сих пор эти исследования, ни к чему реально работающему не привели. Последние три, основанные на методах генной инженерии, имеют гораздо большие перспективы, но работа в этих областях началась только пять лет назад (особенно продвинулись в этом вопросе Массачусетский технологический институт, лаборатории Беркли, лаборатории Рокфеллера, а также Техасский университет).
2.2. Истоки. Расцвет биотехнологии
В конце 90-х годов японцы публикуют сногсшибательную новость: впервые в мире ведутся работы по созданию биокомпьютера, принцип действия которого основан на биологических датчиках. Раньше никто и подумать не мог о такой технологии, так как для нормального функционирования живых организмов требуется постоянное поддержание необходимых условий (температуры, обмена веществ и т.д.). Казалось бы, искусственно создать такой организм невозможно, поэтому новость вызвала большое удивление.
После многочисленных исследований ученые решили использовать в качестве биодатчиков белковые соединения. Несмотря на то, что поддержать их “живучесть” крайне сложно, был найден выход из положения. Как показали эксперименты, сферическая молекула белка способна выдерживать невероятные нагрузки и быть неприхотливой к любым внешним раздражениям (в том числе и химическим). Особенность такого датчика - упругость, которая различна во всех направлениях.

Рис 2. «Белковые соединения»
2.3. Потенциальные возможности
Если сравнивать потенциальные возможности биокомпьютера и обычного компьютера, то первый значительно опережает своего теперешнего собрата. Плотность хранения информации в ДНК составляет 1 бит/нм2 - в триллион раз меньше, чем у видеопленки. ДНК может параллельно выполнять до 1020 операций в секунду - сравнимо с современными терафлоповыми суперкомпьютерами. Кроме ДНК (хотя ДНК-компьютер наиболее популярен среди разработчиков), в качестве компьютерной биопамяти могут выступать другие биологически активные молекулы, например, бактериородопсин, обладающий превосходными голографическими свойствами и способный выдерживать высокие температуры. На его основе уже создан вариант трехмерного запоминающего устройства. Молекулы бактериородопсина фиксируются в гидрогелевой матрице и облучаются двумя лазерами (см. рис 1).
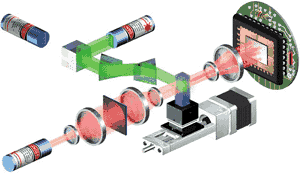
Рис 3. «Устройство компьютерной биопамяти»
Первый лазер (направленный аксиально на гидрогелевый образец) инициирует фотохимические реакции в молекуле и записывает информацию. Второй же, направленный перпендикулярно, считывает информацию, записанную на молекулах бактероиродопсина, находящегося в объеме гидрогеля.
Парадоксально, но по подсчетам, производительность аналогового биопроцессора невелика. Скорость прохождения сигнала по нервному узлу составляет всего 20 м/c, что в пересчете на цифровой эквивалент составляет всего 10² операций в секунду. Супермощные цифровые процессоры способны обработать до 10 в 9 операций. Казалось бы, конкурировать с ними бесполезно.
Но не все так плохо. Когда речь идет, например о фиксации градуса в напитке, цифровой процессор не способен ее быстро выполнить (даже с обычными механическими датчиками). Это связано с тем, что на молекулярном уровне частицы взаимодействуют между собой, порождая новые соединения. Математические расчеты не могут предугадать исход таких реакций, поэтому время, затрачиваемое на изучение вещества, возрастает в геометрической прогрессии. Так что с математической методикой приготовления коктейля с заданным вкусом результат придется ждать неделю,а то и больше.
Вот тут и показывает себя аналоговый камешек. Если на кусочке процессорной пленки размером 1 см² будет содержаться 10 в 12 активных белковых частиц, мы получаем колоссальную производительность, намного превышающую возможности цифрового процессора. Так, например, при пропускании сигнала с датчика даже с минимальной скоростью имеем порядка 10 в 10 переключений, что во много раз превышает возможности электроники. К тому же, никаких проблем с решением задачи у процессора не возникает.
Определив наличие сладкого по вкусу вещества, датчик подает определенный сигнал. Его улавливает процессор, который трансформирует показания биосенсора в цифровой формат. Зная Фон-Неймовскую архитектуру, ты представляешь, что камень может работать напрямую только с ячейками памяти. В биокомпьютере она имеется и носит название оптической или биопамяти.
Долгое время ученые выводили такую белковую структуру, которая была способна выдерживать большие нагрузки (они были необходимы для записи данных). Когда, наконец, подходящие ферменты были найдены, стало вполне реальным создать биопамять, вмещающую в себя гораздо большие объемы информации, чем цифровые мозги.
Глава 3
Строение биокомпьютера
3.1. Архитектура биокомпьютера
Представим архитектуру самого простого биокомпьютера. Это ряд биологических сенсоров (датчиков), которые реагируют на внешнее воздействие. Остановимся на датчиках подробнее. Существует четыре вида датчиков, используемых в биокомпьютерах. Все они необходимы для того, чтобы снабдить компьютер органами чувств:
1. Химический
. Аналог вкусовых рецепторов. Сродни языку, химические датчики способны улавливать состав того или иного вещества, пропускаемого через фермент. Таким образом, можно без проблем определить, какой ингредиент будет добавлен в исследуемое вещество: сладкий или горький;
2. Оптический
. Подобно глазам, белок может определить вид вещества и даже его форму. Это опять-таки фиксируется дальнейшими составляющими биомашины. Благодаря такой фиксации, компьютер реагирует на раздражение должным образом;
3. Механический
датчик служит для осязательных рефлексов. Благодаря такому сенсору машина может двигаться и принимать какие-либо решения после срабатывания других датчиков;
4. Электрический сенсор
служит для передачи сигнала с датчика на следующий компонент биокомпьютера.
Этот компонент называется биопроцессор. Его задача обрабатывать сигнал и преобразовывать его в цифровой вид. В обратном процессе он принимает сигнал с ЭВМ и передает его датчику (в аналоговом виде). И, наконец, процессор взаимодействует с особой структурой белка - биопамятью, которая способна накапливать колоссальные объемы информации за предельно короткое время. Цифровая ЭВМ управляет механическими процессами (например, прекращает подачу того или иного ингредиента при его избытке). Правильнее сказать, цифровой компьютер посылает сигнал механическому биодатчику, после которого компьютер должным образом реагирует на раздражение.
Несмотря на всю сложность, биокомпьютеры только начали развиваться, и пик технологии намечается лишь через 30-50 лет. Уже были проведены эксперименты, результаты которых говорят о том, что создать автономный искусственный интеллект (без электроники) вполне реально.
Можно с уверенностью сказать, что в момент расцвета биоинформатики электронные ЭВМ станут вчерашним днем. Почти как ламповые суперкомпьютеры в наше время. Конечно, наряду с биотехнологиями возьмут верх квантовые и нейрокомпьютеры, которые также являются принципиально новыми разработками.
3.2. Архитектура биопроцессора
В устройстве биодатчика нет ничего сложного. Все подчиняется правилам обычного вычислительного процесса. Он состоит из трех шагов: получение входных данных, обработка результатов и исполнение какого-либо решения.
Вводить данные с клавиатуры очень долго, именно поэтому был придуман биодатчик, который занимается приемом входных данных. Как только происходит изменение формы либо цвета белка, это мгновенно фиксирует биопроцессор, который преобразует сигнал из аналогового в цифровой вид. Такой процессор состоит из специального белкового раствора, который способен непрерывно менять свое состояние. Это не что иное, как аналог транзисторного цифрового камня. Частички белка мгновенно изменяют свое состояние (как правило, цвет). Для нормального функционирования требуется быстрый обратимый процесс, то есть способность частицы вернуть свое прежнее состояние. Ученые очень долго искали подобную структуру, проводя множество долгих экспериментов. Процесс обработки информации похож на горение бикфордова шнура - он продолжается, пока вся пороховая начинка не выгорит. Представьте себе, что порох наделен способностью автоматического восстановления, а шнур замкнут в кольцо. При таком раскладе горение будет вечным, что и необходимо. Ученые долго шли к созданию такого процессора - подобрать нужный состав белка было крайне проблематично (поиск нужной реакции начался с 1956 года).

Рис 4. «Модель биопроцессора»
Биопроцессор имеет три преимущества, благодаря которым применяется в архитектуре машины.
1. Быстродействие
. Как уже было сказано, аналоговый камешек мгновенно принимает решения, которые не под силу цифровому процессору.
2. Надежность
. Если кремниевый процессор мог допускать ошибки при вычислениях, биопроцессор практически не ошибается в своих преобразованиях (максимальная относительная погрешность колеблется от 0,001 до 0,02%).
3. Компактность
. Размеры очень малы. Благодаря тому, что производители научились наслаивать белковую структуру, габариты такого камешка могут быть сопоставимы по размеру с каплей воды.
Правда, у биопроцессора есть и недостатки. В первую очередь, это трудоемкое производство, а также высокая цена.
3.3. Живая память
Очень важной составляющей биокомпьютера является машинная память. Она также имеет белковую структуру, но уже более неприхотливую. Микролазер, который прикреплен к пленке с ферментом, прожигает белок, изменяя его свойства (опять же обратимо). Если подсчитать предельный объем такой памяти в цифровом формате, то мы получим цифру 10^64 бит/см^3, что равняется объему нескольких десятков тысяч книг. Единственный недостаток такой памяти - ее цена и трудоемкое производство.
3.4. Начинка
Весьма интересным вопросом является состав белковых соединений. В биодатчиках применяются белки из так называемых архебактерий. Этот вид давно интересовал ученых, так как микроорганизмы довольно активно реагировали на любые внешние изменения, не утрачивая своих жизненных свойств. Единственным недостатком является то, что в последнее время такие бактерии мутируют в непонятные микроорганизмы (видимо, сказывается экология). Лишь благодаря процессу клонирования, ученые добывают необходимое количество “правильного” белка для производства микродатчиков.

Рис 5. «Архебактерии»
Биопамять состоит из мельчайших частиц бактериородопсина. Этот материал не имеет склонности к разрушению при высоких температурах, поэтому без проблем прожигается лазером.
Рис 6. «Структура бактериородопсина»
Глава 4
Виды биокомпьютеров
Идут разработки нескольких типов биокомпьютеров, которые базируются на разных биологических процессах. Это, в первую очередь, находящиеся в стадии разработки ДНК- и клеточные биокомпьютеры.
4.1. ДНК-компьютеры
Как известно, в живых клетках генетическая информация закодирована в молекуле ДНК (дезоксирибонуклеиновой кислоты). ДНК - это полимер, состоящий из субъединиц, называемых нуклеотидами. Нуклеотид представляет собой комбинацию сахара (дезоксирибозы), фосфата и одного из четырех входящих в состав ДНК азотистых оснований: аденина (А), тимина (Т), гуанина (G) и цитозина. Молекула ДНК образует спираль, состоящую из двух цепей, объединенных водородными связями. При этом основание А одной цепи может соединяться водородными связями только с основанием Т другой цепи, а основание G - только с основанием С. То есть, имея одну из цепей ДНК, всегда можно восстановить строение второй. Благодаря этому фундаментальному свойству ДНК, получившему название комплементарности, генетическая информация может точно копироваться и передаваться от материнских клеток к дочерним. Репликация молекулы ДНК происходит за счет работы специального фермента ДНК-полимеразы. Этот фермент скользит вдоль ДНК и синтезирует на ее основе новую молекулу, в которой все основания заменены на соответствующие парные. Причем фермент начинает работать только если к ДНК прикрепился коротенький кусочек-затравка (праймер). В клетках существует также родственная молекуле ДНК молекула матричной рибонуклеиновой кислоты (РНК). Она синтезируется специальным ферментом, использующим в качестве образца одну из цепей ДНК, и комплементарна ей. Именно на молекуле РНК в клетке, как на матрице, с помощью специальных ферментов и вспомогательных факторов происходит синтез белков.

Рис 7. «Молекула ДНК»
Молекула РНК химически устойчивее, чем ДНК, поэтому экспериментаторам с ней работать удобнее. Последовательность нуклеотидов в цепи ДНК/РНК определяет генетический код. Единицей генетического кода - кодоном - является последовательность из трех нуклеотидов. Ученые решили попытаться по примеру природы использовать молекулы ДНК для хранения и обработки данных в биокомпьютерах.

Рис 8. «Схема ДНК-компьютера»
В конце февраля 2002 г. появилось сообщение, что фирма Olympus Optical претендует на первенство в создании коммерческой версии ДНК-компьютера, предназначенного для генетического анализа. Машина была создана в сотрудничестве с доцентом Токийского университета Акирой Тояма. Компьютер, построенный Olympus Optical, имеет молекулярную и электронную составляющие. Первая осуществляет химические реакции между молекулами ДНК, обеспечивает поиск и выделение результата вычислений. Вторая - обрабатывает информацию и анализирует полученные результаты.
Анализ генов обычно выполняется вручную и требует много времени: при этом формируются многочисленные фрагменты ДНК и контролируется ход химических реакций. “Когда ДНК-компьютинг будет использоваться для генетического анализа, задачи, которые ранее выполнялись в течение трех дней, можно будет решать за шесть часов”, - сказал сотрудник Olympus Optical Сатоши Икута. В компании надеются поставить технологию генетического анализа на основе ДНК-компьютера на коммерческую основу. Она найдет применение в медицине и фармации. Ученые планируют внедрять молекулярные наноустройства в тело человека для мониторинга состояния его здоровья и синтеза необходимых лекарств.
4.2. Клеточные компьютеры
Еще одним интересным направлением является создание клеточных компьютеров. Для этой цели идеально подошли бы бактерии, если бы в их геном удалось включить некую логическую схему, которая могла бы активизироваться в присутствии определенного вещества. Такие компьютеры очень дешевы в производстве. Им не нужна столь стерильная атмосфера, как при производстве полупроводников. И единожды запрограммировав клетку, можно легко и быстро вырастить тысячи клеток с такой же программой.
В 2001 г. американские ученые создали трансгенные микроорганизмы (т. е. микроорганизмы с искусственно измененными генами), клетки которых могут выполнять логические операции И/ИЛИ.
Рис 9. «Клетка как компьютер»
Специалисты лаборатории Оук-Ридж, штат Теннесси, использовали способность генов синтезировать тот или иной белок под воздействием определенной группы химических раздражителей. Ученые изменили генетический код бактерий Pseudomonas putida таким образом, что их клетки обрели способность выполнять простые логические операции. Например, при выполнении операции И в клетку подаются два вещества (по сути - входные операнды), под влиянием которых ген вырабатывает определенный белок. Теперь ученые пытаются создать на базе этих клеток более сложные логические элементы, а также подумывают о возможности создания клетки, выполняющей параллельно несколько логических операций.
Глава 5
Аргументы за и против введения новой технологии
Потенциал биокомпьютеров очень велик. По сравнению с обычными вычислительными устройствами они имеют ряд уникальных особенностей. Во-первых, они используют не бинарный, а тернарный код (так как информация в них кодируется тройками нуклеотидов). Во-вторых, поскольку вычисления производятся путем одновременного вступления в реакцию триллионов молекул ДНК, они могут выполнять до 1014 операций в секунду (правда, извлечение результатов вычислений предусматривает несколько этапов очень тщательного биохимического анализа и осуществляется гораздо медленнее). В-третьих, вычислительные устройства на основе ДНК хранят данные с плотностью, в триллионы раз превышающей показатели оптических дисков. И наконец, ДНК-компьютеры имеют исключительно низкое энергопотребление.
Однако в разработке биокомпьютеров ученые столкнулись с целым рядом серьезных проблем. Первая связана со считыванием результата - современные способы секвенирования (определения кодирующей последовательности) не совершенны: нельзя за один раз секвенировать цепочки длиной хотя бы в несколько тысяч оснований. Кроме того, это весьма дорогостоящая, сложная и трудоемкая операция.
Вторая проблема - ошибки в вычислениях. Для биологов точность в 1% при синтезе и секвенировании оснований считается очень хорошей. Для ИТ она неприемлема: решения задачи могут потеряться, когда молекулы просто прилипают к стенкам сосудов; нет гарантий, что не возникнут точечные мутации в ДНК, и т. п. И еще - ДНК с течением времени распадаются, и результаты вычислений исчезают на глазах! А клеточные компьютеры работают медленно, и их легко “сбить с толку”. Со всеми этими проблемами ученые активно борются. Насколько успешно - покажет время.
Биокомпьютеры не рассчитаны на широкие массы пользователей. Но ученые надеются, что они найдут свое место в медицине и фармации. Глава израильской исследовательской группы профессор Эхуд Шапиро уверен, что в перспективе ДНК-наномашины смогут взаимодействовать с клетками человека, осуществлять наблюдение за потенциальными болезнетворными изменениями и синтезировать лекарства для борьбы с ними.
Наконец, с помощью клеточных компьютеров станет возможным объединение информационных и биотехнологий. Например, они смогут управлять химическим заводом, регулировать биологические процессы внутри человеческого организма, производить гормоны и лекарственные вещества и доставлять к определенному органу необходимую дозу лекарств.
Заключение
Использование биокомпьютера уже сегодня возможно, целесообразно и необходимо: в науке, образовании, во всех системах управления, проектирования, в процессах созидания и творения.
С его помощью, например, можно получить полную информацию о состоянии здоровья каждого элемента своего организма, отклонения не от средней нормы, а от нормы данного человека в процентах и узнать причину этих отклонений. Клиент может сделать заказ пользователю биокомпьютера по телефону, факсу из любой точки земного шара и таким же способом получить распечатанный ответ.
В спорте, искусстве, шоу-бизнесе по фамилии, имени и отчеству можно получить полную информацию об успехе, возможностях, совместимости с коллективом приобретаемого кандидата в клуб или коллектив. Фактически уже открыто новое направление – геология интеллектуальных ресурсов стран, и это самое главное их богатство.
Для крупных объединений, корпораций только с помощью биокомпьютерных технологий можно разработать прогнозы их развития, выявить новые направления деятельности с учетом будущих реалий нашего мира. Очень важным обстоятельством при выполнении подобных работ является то, что биокомпьютерные технологии не требуют исходной статистической и тем более коммерчески закрытой информации.
Для решения научных проблем биокомпьютер заменит все технические средства научных проблемных лабораторий, оставив им решать незначительные прикладные задачи.
Биокомпьютерные технологии привлекательны тем, что практически все задачи решаются оперативно.
8. Кузнецов Е. Ю., Осман В. М. Персональные компьютеры и программируемые микрокалькуляторы: Учеб. пособие для ВТУЗов - М.: Высш. шк. -1991
Сущ., кол во синонимов: 1 компьютер (52) Словарь синонимов ASIS. В.Н. Тришин. 2013 … Словарь синонимов
биокомпьютер - Компьютер, основными компонентами которого являются биомолекулы. Уменьшение размеров компонентов интегральных схем с помощью современных технологий подходит к своему пределу. Поэтому внимание исследователей привлечено к проблеме использования… … Справочник технического переводчика
Биокомпьютер Эдлмана
ДНК-компьютер - ДНК компьютер вычислительная система, использующая вычислительные возможности молекул ДНК. Содержание 1 Биокомпьютер Адлемана 2 Конечный биоавтомат Бененсона Шапиро … Википедия
Конечный биоавтомат Шапиро - ДНК компьютер вычислительная система, использующая вычислительные возможности молекул ДНК. Содержание 1 Биокомпьютер Адлемана 2 Конечный биоавтомат Шапиро 3 См. также … Википедия
Компьютер - Схема персонального компьютера: 1. Монитор 2. Материнская плата 3 … Википедия
Классы компьютеров - Типы компьютерных корпусов XT AT ATX eATX FlexATX miniATX microATX BTX MicroBTX PicoBTX DTX Mini DTX ETX LPX Mini LPX NLX ITX Mini ITX Nano ITX Pico ITX PC/104 / Plus … Википедия
Buttobi!! CPU - ぶっとび!!CPU (Буттобу!!CPU) Жанр комедия … Википедия
Персональный компьютер - Запрос «PC» перенаправляется сюда; см. также другие значения. Иное название этого понятия «ПК»; см. также другие значения. Эта статья обо всех видах ПК. О самой распространённой платформе см. IBM PC совместимый… … Википедия
Консольный компьютер - (англ. frontend computer) компьютер, выполняющий подготовительные действия, необходимые для запуска основной компьютерной системы. Такие функции могут выноситься на отдельную машину при создании «больших» компьютерных систем, например … Википедия
Книги
- Биокомпьютер человека: Состав, структура, свойства Купить за 474 грн (только Украина)
- Биокомпьютер человека. Состав, структура, свойства , Селезнева Н.В.. Настоящая книга содержит результаты бионических исследований физических, функциональных и информационных свойств интеллекта человека, процессов мышления, творчества и накопления опыта и…
Биокомпьютеры будут управлять гигантскими заводами, странами и поведением людей. Компьютерами будущего станут ДНК и бактерии.
Учёные уже определились, как можно будет обойти закон Мура, согласно которому количество транзисторов, размещаемых на кристалле интегральной схемы, удваивается каждые два года.
Закон предсказывает, что к 2060 г. элементы микросхемы станут размером с атом, что невозможно с точки зрения квантовой механики. Хотя произойти это может гораздо раньше.
За последние несколько лет период удвоения производительности сократился с двух до полутора лет.
Впрочем, сам Гордон Мур еще в 2007 г. высказал мысль, что его закон скоро перестанет действовать из-за атомарной природы вещества и ограничения скорости света. Однако это не означает остановку технического прогресса. Принципиально новый его этап начнется, когда человечество откажется от квантових компьютеров в пользу биологических.
Биокомпьютеры — своеобразный гибрид информационных технологий и биологических систем
Исследователи биологии, физики, химии, генетики — используют природные процессы для создания искусственных вычислительных схем. Согласно прогнозу агентства IDC к 2020 г. объём данных, созданных и сохраненных человечеством, достигнет 40 000 эксабайт. Это 40 трлн гигабайт, или по 5200 гигабайт на человека.
Для хранения такого объёма информации было бы достаточно менее 100 г ДНК. Вычислительная мощность ДНК-процессора размером с каплю превышает возможности самых продвинутых суперкомпьютеров.
Более 10 трлн ДНК-молекул занимают объём всего в 1 куб. см. Такого количества достаточно для хранения объёма информации в 10 Тбайт, при этом они могут производить 10 трлн операций в секунду.
Ещё одно преимущество ДНК-процессоров в сравнении с обычными кремниевыми заключается в том, что триллионы молекул ДНК, работая одновременно, могут производить все вычисления не последовательно, а параллельно, что обеспечивает моментальное выполнение сложнейших математических расчётов (до 1014 операций в секунду).
Теоретически кодировать информацию в молекулах несложно: по сути, это происходит по аналогии с обычным программированием. Современные компьютеры работают с бинарной логикой: используя последовательность нулей и единиц, можно закодировать любую информацию.
В молекулах ДНК имеется четыре базовых основания: аденин (A), гуанин (G), цитозин (C) и тимин (T), связанных в цепочку. При кодировании информации на молекуле ДНК используется четверичная логика.
Как современные микропроцессоры имеют набор базовых функций типа сложения, сдвига, логических операций, так ДНК-молекулы под воздействием энзимов могут выполнять такие базовые операции, как разрезание, копирование, вставка и т. п.
Причём разные манипуляции с ДНК-молекулами идут параллельно — они не будут влиять друг на друга. Это необходимо для решения многоуровневых задач.
Экспериментов было немало, причём использовались не только ДНК, но и РНК. Ученые Принстонского университета заставили молекулы рибонуклеиновой кислоты решать комбинаторную шахматную задачу. РНК нашли правильный ход шахматного коня на доске из 512 вариантов.
Первый «физически осязаемый» биокомпьютер в 1999 г. создал профессор Ихуд Шапиро Вейцмановского института естественных наук. Пластмассовая модель имитировала работу молекулярной машины в живой клетке.
В 2001-м Шапиро удалось воплотить систему в реальном биокомпьютере, который состоял из молекул ДНК, РНК и специальных ферментов. Молекулы фермента выполняли роль аппаратного, а молекулы ДНК — программного обеспечения. При этом в одной пробирке помещалось около триллиона элементарных вычислительных модулей.
В результате скорость вычислений достигла миллиарда операций в секунду, а точность — 99,8%. Но биокомпьютер Шапиро может применяться лишь для решения самых простых задач, выдавая всего два типа ответа: «истина» или «ложь».
В конце февраля 2002 г. появилось сообщение, что японская фирма Olympus Optical в сотрудничестве с профессором Токийского университета Акирой Тоямой претендует на первенство в создании коммерческой версии ДНК-компьютера. Обычно анализ генов выполняется вручную и занимает более трёх дней: Биосистема же способна выполнять все необходимые расчёты всего за шесть часов.
Результаты более свежих исследований и достижений в этой сфере остаются засекреченными. Из дозированных сообщений известно лишь, что учёные работают над решением двух принципиальных задач, без ответа на которые невозможно создать полноценный биокомпьютер. Первая — организация клеток в единую рабочую систему. Вторая — быстрое и правильное извлечение сохраненной информации.
Биокомпьютер заменит все традиционные технические средства
Биокомпьютеры произведут революцию не только в IT-сфере, но и во многих других отраслях.
Учёные уверены, что в перспективе ДНК-машины смогут взаимодействовать с клетками человека, осуществлять наблюдение за потенциальными болезнетворными изменениями и синтезировать лекарства для борьбы с ними, производить гормоны и доставлять определенную дозу препарата к конкретному органу.
Психиатры говорят о возможности внедрения крошечных биомашин в организм человека для лечения психических расстройств, а со временем и для коррекции поведенческих реакций.
С помощью клеточных компьютеров можно будет объединить технологии для управления предприятиями всех видов продукции. Причём всего за несколько часов можно будет проанализировать эффективность деятельности огромного завода, просчитать конкурентоспособность основных видов товаров и необходимость расширения производства.
Биокомпьютерные технологии в бизнесе, науке, производстве и даже в управлении государством позволят моментально найти наилучшие решения — это избавит мир от фатальных проблем, связанных с неумелым руководством.
Способность получать как можно больше пользы за счёт технологий